Spänningen är olidlig
Svenska språket lyder sina egna lagar. Det blir tydligt när man vill utse svenskans vanligaste ord. Två kandidater tävlar om titeln, och språkvetaren Lars Melin står redo att ta målfotot.

Vilket är svenskans vanligaste ord? Bara att räkna? Nej, räkna ord är svårare än de flesta tror. Så för att avgöra detta verkar det nödvändigt att kalla in en måldomare. Det finns två kandidater i stallet.
Den ena är det mångsidiga och flexibla ordet och. Detta ovanligt vanliga ord är den riktiga lågoddsaren i racet (se Språktidningen 5/15).
Lilla i har däremot visat sig vara en farlig medtävlare. Ja, just lilla. Det finns inte så många svenska ord på en bokstav. Egentligen bara å, ö – och så lilla i.
I konkurrensen om korthet vinner alltså ordet i överlägset. Ett gement å eller ö tar minst dubbelt så mycket plats som ett i, och med versala tecken är det ännu större skillnad. Om man kunde väga i:et skulle det vara ordet med oslagbart BMI-värde.
Det är alltså denna minsting som tävlar med och om titeln ”svenskans vanligaste ord”. Några som borde kunna utse en vinnare är personerna bakom Språkbanken i Göteborg (spraakbanken.gu.se). De har ägnat de senaste femtio åren åt att bygga upp små, stora och gigantiska digitaliserade ordsamlingar – förlåt, korpusar ska det heta – i vilka man kan söka och räkna ord i texter från 1700-talet och framåt.
I Språkbankens första mätning, som ägde rum 1965, visade sig och vara svenskans vanligaste ord. Däremot segrade det till synes obetydliga i:et när man mätte år 1976, 1987 och 1994–96.
Det finns någonting mycket märkligt i detta. Att ett språk inte har en självklar etta går nämligen emot en av språkvetenskapens grundlagar: Zipfs lag. Den stadgar att det allra vanligaste ordet i ett språk ska vara ungefär dubbelt så vanligt som tvåan och tvåan dubbelt så vanligt som trean och så vidare ända ner i det så kallade hapaxträsket. Här har orden bara en endaste förekomst i en viss text eller textsamling. Hapax är för övrigt det grekiska ordet ἅπαξ som betyder ’en gång’. Det är nere i den anonymiteten som de allra flesta ord finns.
Zipfs lag stämmer i princip för engelska och för ett stort antal andra språk. The är det mest frekventa ordet i engelska, med en förekomst på cirka 7 procent av orden i en normal text, medan det näst vanligaste ordet, of, står för drygt 3,6 procent (alltså nästan prick hälften av 7), följt av trean and med 2,8 procent (vilket kanske inte är hälften av 3,6 – men det får ändå godkänt).
Ordstatistik är alltså en fascinerande hierarki, där ett enda ord får plats i toppen: the winner takes it all. Men så ej i svenskan!
Diagrammet här nedan visar hur vanliga svenskans 20 vanligaste ord var i tidningstexter 1965. Vi ser och i toppen, precis före i. Dessa två ord har över 30 000 förekomster vardera, på totalt en miljon ord. Efter dessa två ord faller frekvensen drastiskt för resten av ordförrådet. Ordet att på tredje plats har drygt 20 000 förekomster och en knappt 20 000. Också dessa bildar alltså ett par, och längre ner i hierarkin kommer massor med både par och klungor. Efter cirka 10 ord börjar det plana ut.
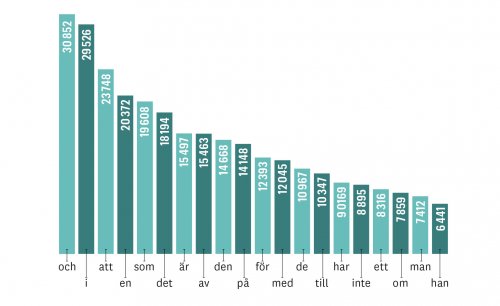
Och så här ser det i princip fortfarande ut efter ett halvsekel, men det är osäkert om och ligger före i, eller om i ligger före och i mer dagsaktuell text. Vi förefaller ha två ganska jämbördiga ord i toppen.
Men trots att Zipfs lag inte verkar gälla för ledarklungan i svenskan 1965, så stämmer den i stora drag för övriga ord. Det kan vi se på störtloppsbacken i diagrammet.
När nu ordningen i toppen ändå är rubbad, måste vi förstås fråga oss hur ett så litet ord som i kan bli så stort, kanske till och med störst.
Att och är vanligt är intuitivt rätt. Vi samordnar hela tiden saker genom att sätta och emellan: Romeo och Julia, Helan och Halvan, gin och tonic … Och vi pladdrar på: och sen sa han, och hon tyckte, och jag höll med … Men en preposition som i? Varför inte lika gärna på, som många uppfattar som svenskans universalpreposition? Det verkar ju inte stämma: på hittar vi flera steg ner i listan – just där det börjar plana ut. Det är i som ligger hack i häl, nästan i fatt.
Surfar man runt man bland de många korpusarna som finns på Språkbanken, så finner man att och oftast toppar i tidningstext, med i:et som vanligaste tvåa – men inte alltid. Det blåser hårt på toppen.
I en gigantisk korpus av Statens offentliga utredningar, 426 miljoner ord skön byråkratprosa, vinner i med 10 miljoner förekomster mot och:s futtiga 8 miljoner. Å andra sidan vinner och när man söker i Bloggmix 2013, som är en jättekorpus på 34 miljoner ord. Där finns en miljon och medan det bara finns en halv miljon i. Dubbelt upp, precis som det ska vara om Zipf får bestämma.
Sedan kan man fortsätta sin jakt på vinnaren genom att söka i Bonniersromaner från 1980-talet, som Språkbanken har samlat ihop i en korpus på 4,3 miljoner ord. Där visar det sig också att och ligger i täten. Ordet förekommer 136 000 gånger i materialet, medan lilla i dyker upp 83 000 gånger. Det är inte riktig Zipf-fördelning, men åt det hållet.
Den historiskt intresserade bör känna till att och var det vanligaste ordet redan på svenska runstenar. Men i den allra första frekvensundersökningen av svenska ord – Olof Werling Melins studie av 1891 års riksdagsprotokoll – ledde att över i, medan och hamnade först på tredjeplats.
Ett stickprov bland dagens riksdagsprotokoll visar att riksdagsledamöter – fortfarande efter mer än hundra år – fortfarande gillar att tala i att-satser. Att hamnar alltjämt på plats 1.
Zipf ser bekymrad ut när det dyker upp fler bubblare i toppen, men politiker rår inte ens Zipf över.
Trenden är klar. Och är vardagsbloggarnas och romanförfattarnas favoritord, medan i trivs allra bäst i den stela och formella prosan, som byråkrater och politiker älskar. Tidningarna, å sin sida, väger mellan de bägge orden.
Detta säger något viktigt om språket. Vi har i princip två sätt att bygga ut fraser: samordning och underordning. Till vardags föredrar vi samordning. Med detta menas att vi sätter ihop två ord, satser och meningar (som har samma funktion) bland annat med hjälp av och. Men ju mindre vardagliga och mer formella vi blir, desto mer gillar vi att underordna, det vill säga låta ett ord eller en fras säga något mer om en annan fras, som i Nisse. Vilken Nisse? Jo, Nisse i styrelsen.
I fikarummet:
Det är bara strul och stopp i systemet. Och pengar kostar det. Vi skrotar det och tar nåt annat.
I sammanträdesrummet:
Antalet buggar i systemet och kostnaderna i jämförelse med andra operativsystem på marknaden talar för att vi bör betänka alternativ.
Vid kaffebordet gör vi fyra och-samordningar medan sammanträdet får en enda. Vid kaffebordet finns bara en fras som hålls ihop av preposition (stopp i systemet). Men formellt språk älskar långa fraser som oftast byggs upp med hjälp av prepositioner: buggar i systemet; kostnaderna i jämförelse med andra system på marknaden.
Vill man parodiera formellt språk finns det alltså två styrspakar: dra ner och-spaken och dra upp prepositionsspaken.
Men i detta frasbygge har i:et knappast några fördelar framför andra prepositioner. I:ets toppnotering måste ha flera orsaker. Låt oss begrunda några.
I:et har till exempel nästan lyckats monopolisera tidsuttryck: i dag, i kväll, i år, i fjol, i sinom tid, i framtiden … Texter som håller ordning på tiden innehåller alltså med nödvändighet många i. I:et positionerar sig även i vardagliga tidsuttryck som i ett huj, i rödaste rappet, i tid och otid, i detta nu. Och förstås i ett annat fast uttryck, i:ets tagline: hack i häl.
Dessutom tar i:et hem storslam i fraser som förekommer flitigt i formell text: i och med, i stort, i förhållande till, i sak och i praktiken. Och för säkerhets skull garderar i:et med lite mer vardagliga fraser som i alla fall, i och för sig, i runda slängar.
Och inte nog med detta. I:et är inte bara en preposition, utan också så kallad verbalpartikel. Partiklar är, till skillnad från prepositioner, alltid betonade, och de ingår i en så kallad verbfras. Och just som partikel visar sig i:et från sin starkaste sida: ligga i, ta i, hugga i. Energin sprutar, och i:et kommer kanske inte först i mål – men nästan i fatt. Eller så går det om och. Vi får väl se!
Det var många förklaringar till i:ets särställning. Men räcker de? Nej, i:et är smartare än så. Det har ännu inte spelat ut sitt starkaste kort: ordet är så litet att det inte kan förkortas. En förkortad fras som i st f (i stället för) ger en poäng till i:et vid en sökning – men prepositionskollegan för kammar noll.
I tycks vara i form. Men räcker det för annat än etappsegrar? Sorry, det är och som har både bredden och djupet. Jag hänvisade ovan till en undersökning på flera hundra miljoner bloggord. Detta är så nära man kan komma vanliga svensktalandes vanliga, vardagliga språk i vanliga, vardagliga situationer. Och:s seger där är ingen tillfällighet.
Alla Språkbankens bloggmixkorpusar har och i toppen. Detta material är också ordrikare än samtliga tidningskorpusar tillsammans, med långt över en halv miljard ord.
så om något annat ord än och tillfälligtvis vinner är det något snett med materialet: för formellt, för komplext, för kompakt eller något annat. Och är garanten för att en text är ”normal”. Och Zipf håller ivrigt med.
Ja, då har vi fått lite stalltips från i-spiltan, samtidigt som vi vet att och har låga, säkra odds. Det ser jämnt ut, men vad säger domarna på Språkbanken? Vem tar hem segerpokalen i svenskans nutida texter? Och eller i? Spänningen är olidlig.
Måldomarna Gerlof Bouma och Malin Ahlberg på Språkbanken ställer om parametrarna i sökmotorn en aning för i och och i korpusen med texter från Göteborgs-Posten, GP 2013. En segrare är utsedd! Och får 426 492 förekomster. Men det räcker inte för att slå ettan…
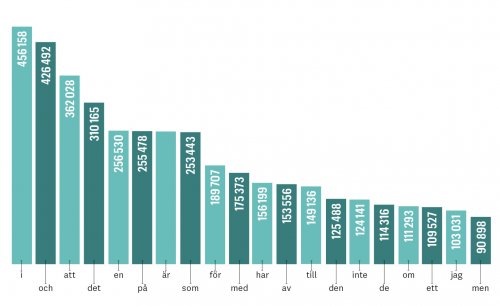
Med 456 158 förekomster vinner lilla i!
Grattiiis!
Lars Melin är docent i svenska vid Stockholms universitet och populärvetenskaplig författare.
Zipfs lag
Zipfs lag har fått sitt namn efter Harvardprofessorn George Kingsley Zipf (1902–50). Den består i själva verket av två lagar.
Lag ett:
1) säger att hälften av orden i en tillräckligt stor text ska vara på en stavelse. Hälften av resten ska vara på två stavelser, och hälften av resten ska vara på tre stavelser och så vidare.
2) säger att ordens frekvenser följer ett mönster som kan beskrivas lite olika.
Lag två:
1) Produkten Frekvens x Rangrummer ska vara en konstant.
2) Frekvensen ökar exponentiellt.
3) Ordet med rangplats 1 ska vara dubbelt så vanligt som ordet med rangplats 2, och detta ord ska vara dubbelt så vanligt som ordet med rangplats 3 och så vidare. Ganska snart finns det flera ord på varje rangplats, men det bryr sig Zipf inte om.
4) Eller varför inte, utan krumbukter, som Zipf själv brukade säga det:
Pn~1/Na
vilket kan uttolkas som fördelningen 1, ½, 1/3, ¼, …, 1/n
(p = rangplatsen och a är en konstant)
Zipfs lag gäller också för många andra saker, som städers folkmängd, förmögenhetsfördelning, massmediers klickvärden och så vidare.































